
Differential gene expression and DESeq2 with Michael Love (#60)
May 12, 2021
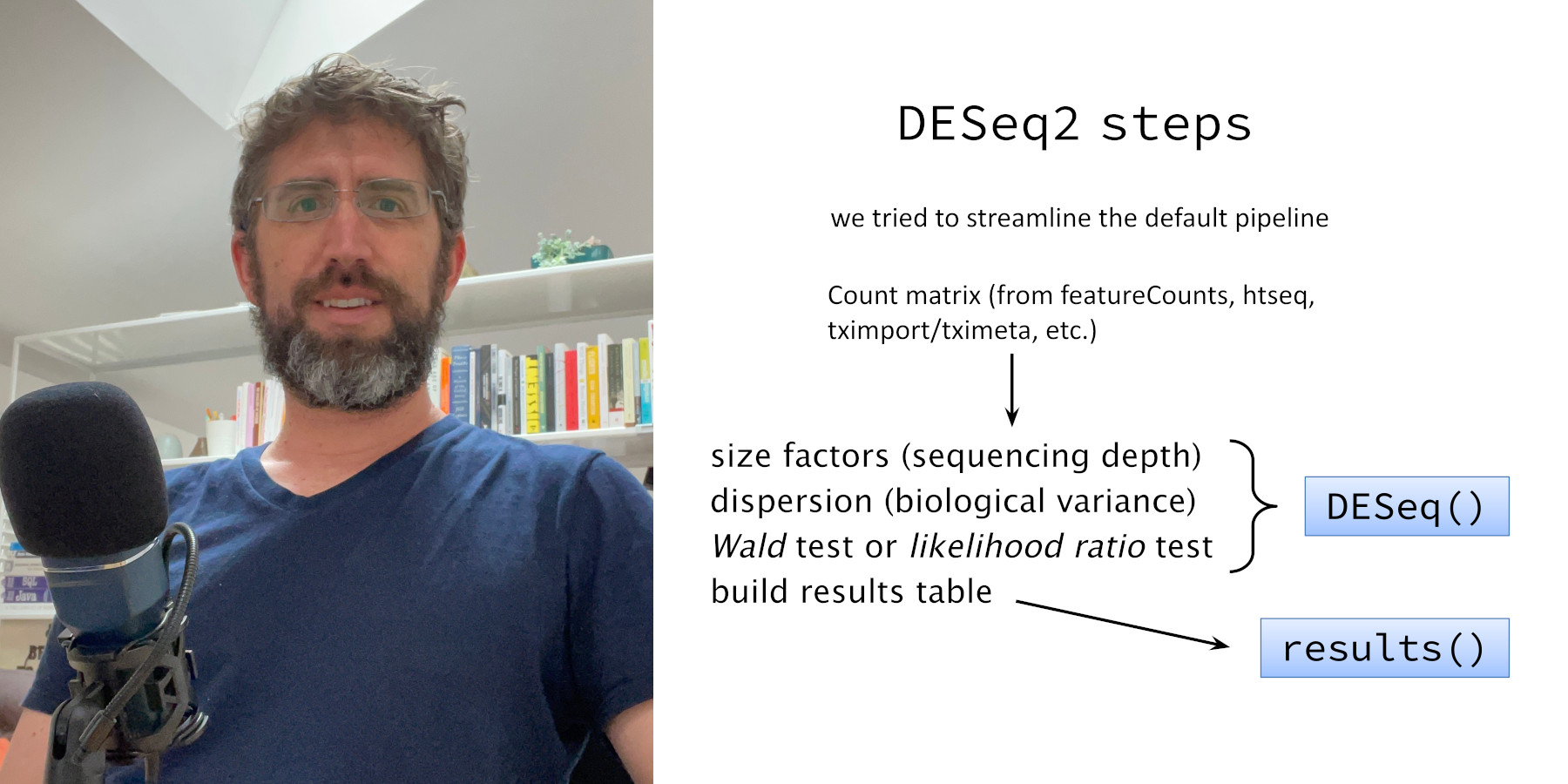
In this episode, Michael Love joins us to talk about the differential gene expression analysis from bulk RNA-Seq data.
We talk about the history of Mike’s own differential expression package, DESeq2, as well as other packages in this space, like edgeR and limma, and the theory they are based upon. Mike also shares his experience of being the author and maintainer of a popular bioninformatics package.
Links:
- Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2 (Love, M.I., Huber, W. & Anders, S.)
- DESeq2 on Bioconductor
- Chan Zuckerberg Initiative: Ensuring Reproducible Transcriptomic Analysis with DESeq2 and tximeta
And a more comprehensive set of links from Mike himself:
limma, the original paper and limma-voom:
https://pubmed.ncbi.nlm.nih.gov/16646809/
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4053721/
edgeR papers:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2796818/
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3378882/
The recent manuscript mentioned from the Kendziorski lab, which has a Gamma-Poisson hierarchical structure, although it does not in general reduce to the Negative Binomial:
https://doi.org/10.1101/2020.10.28.359901
We talk about robust steps for estimating the middle of the dispersion prior distribution, references are Anders and Huber 2010 (DESeq), Eling et al 2018 (one of the BASiCS papers), and Phipson et al 2016:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3218662/ https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6167088/ https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5373812/
The Stan software:
https://mc-stan.org/
We talk about using publicly available data as a prior, references I mention are the McCall et al paper using publicly available data to ask if a gene is expressed, and a new manuscript from my lab that compares splicing in a sample to GTEx as a reference panel:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3013751/ https://doi.org/10.1101/856401
Regarding estimating the width of the dispersion prior, references are the Robinson and Smyth 2007 paper, McCarthy et al 2012 (edgeR), and Wu et al 2013 (DSS):
https://pubmed.ncbi.nlm.nih.gov/17881408/
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3378882/
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3590927/
Schurch et al 2016, a RNA-seq dataset with many replicates, helpful for benchmarking:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4878611/
Stephens paper on the false sign rate (ash):
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC5379932/
Heavy-tailed distributions for effect sizes, Zhu et al 2018:
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6581436/
I credit Kevin Blighe and Alexander Toenges, who help to answer lots of DESeq2 questions on the support site:
https://www.biostars.org/u/41557/
https://www.biostars.org/u/25721/
The EOSS award, which has funded vizWithSCE by Kwame Forbes, and nullranges by Wancen Mu and Eric Davis:
https://chanzuckerberg.com/eoss/proposals/ensuring-reproducible-transcriptomic-analysis-with-deseq2-and-tximeta/
https://kwameforbes.github.io/vizWithSCE/
https://nullranges.github.io/nullranges/
One of the recent papers from my lab, MRLocus for eQTL and GWAS integration:
https://mikelove.github.io/mrlocus/
Music: Eric Skiff — Come and Find Me (modified, licensed under CC BY 4.0).
Subscribe to the bioinformatics chat on Apple Podcasts, Pocket Casts, Spotify, or any other podcasting app via the RSS feed link. You can also follow the podcast on Mastodon and Twitter and support it on Patreon.